Unveiling the Potential of Language Models in LaTeX Synthesis
LaTeX has been one of the de facto standards for the communication and publication of scientific documents. Generating LaTeX code that follows users' intentions is an important task in the digital age, which requires the model to understand user inputs presented in various formats and correctly generate grammatically correct code that can be rendered. Traditional rule-based methods, despite their high accuracy, often limit input to a specific format to generate valid LaTeX code, which substantially reduces the model's applicability. In reality, the same LaTeX expression might be represented in multiple formats such as images or textual descriptions.
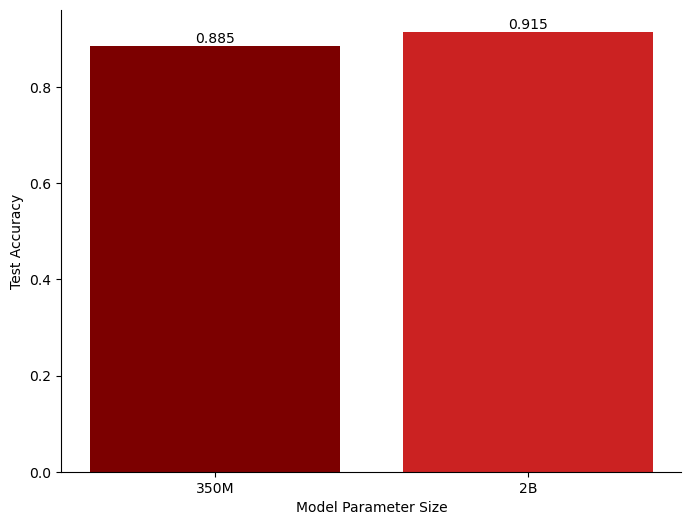
In this work, we investigate LaTeX program synthesis with foundation models that allow flexible inputs represented in texts or images. We propose to use a tree-based approach to generate LaTeX expressions with various diversity and scale. We observe that larger pre-trained models leads to improved performance. With an appropriate model, the prediction accuracy improves with an increase in both the size and complexity of the training set. Specifically, training on just 2500 samples (with a depth of 3) yields promising results, achieving 99.0% accuracy on test sets with expressions of depth-2, compared to 88.5% accuracy when training with the same sample size but a depth-2 input. This suggests the effectiveness of learning-based LaTeX code generation.
Main Results
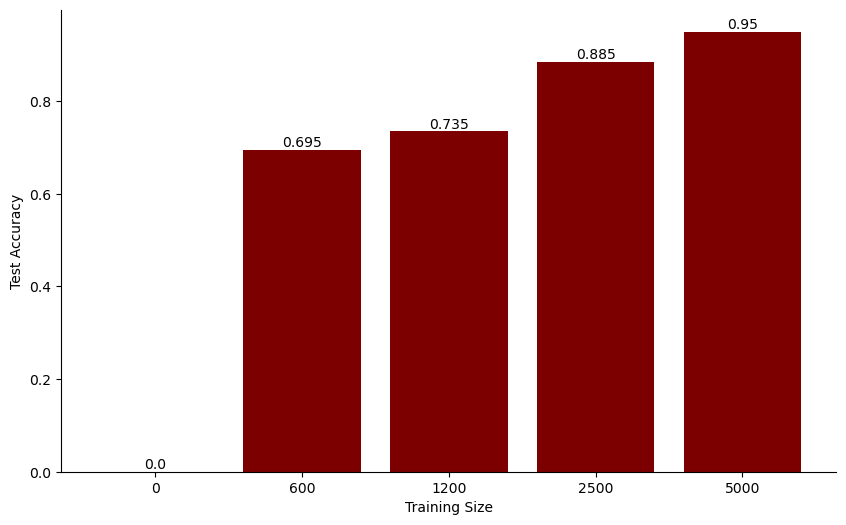
Training on moderate-sized datasets achieves strong code generation performance. Notably, the model displays zero accuracy without fine-tuning (i.e., if we directly evaluate the pre-trained model on the test set without further fine-tuning on our generated dataset). As shown in the figure to the right, when the training dataset size increases, the model's accuracy improves significantly from 0.695 at a training size of 600 to 0.95 at 5,000, which indicates a clear positive correlation between training size and test accuracy. This progression highlights the critical role of fine-tuning in model performance, with larger training datasets significantly enhancing the model’s code generation capabilities, underscoring the adaptability of pre-trained language models.
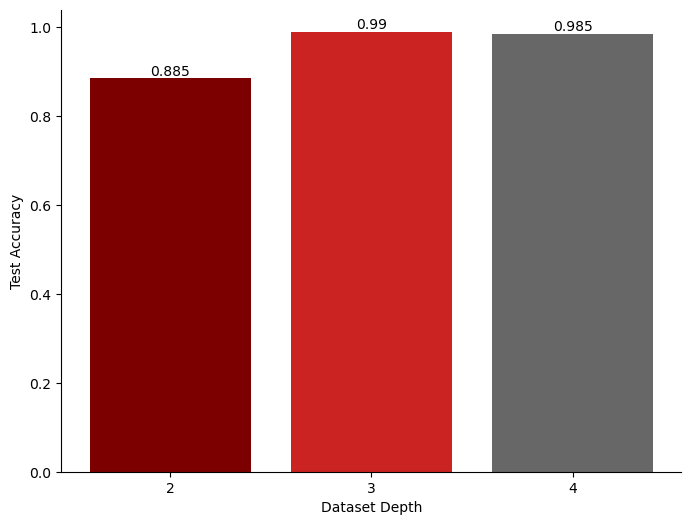
Complexity boosts training effectiveness up to a point. We explored how training set depth affects model success. Models were trained on sets of 2500 samples and tested on a consistent set. As indicated by the figure to the left, accuracy topped at depth 3 (0.99) but dipped slightly at depth 4 (0.985), following an increase from depth 2 (0.885). This implies there is a point where adding complexity ceases to yield significant performance improvements. Pinpointing this balance is key to refining training and maximizing model results.
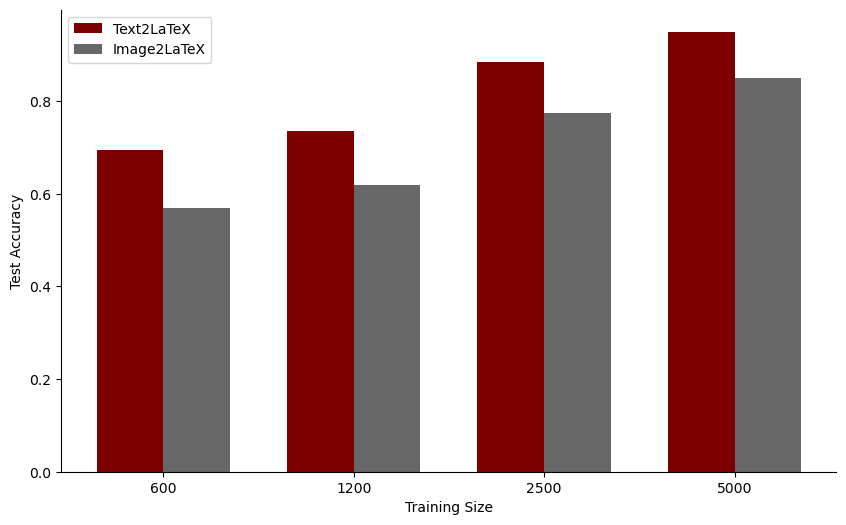
Additional visual information doesn't always enhance performance. Investigating if textual data alone suffices for LaTeX format comprehension, we compared Text2LaTeX and Image2LaTeX models. The key difference lies in Image2LaTeX's extra image input, transformed into visual tokens. Contrary to expectations, adding visual inputs led to a drop in accuracy, as shown by the figure to the left. This suggests visual data might actually distract from processing LaTeX expressions. While a Vision Transformer (ViT) breaks down image inputs into patches, language models seem to manage string inputs more effectively for complex LaTeX expressions.